之前我們探討了 dbt 專案大概是怎麼運作。
然而,其中的第四步驟「開始編輯 $PROJ/models 下的 sql 檔,在其中寫入資料轉換 (data transformation)。之後,如果又有要寫什麼新的資料轉換,就會再回到步驟 4 來寫新的 sql 檔。」
讀者很可能覺得頗為抽象,所以我們這邊要對這個第四步驟做更細的討論。
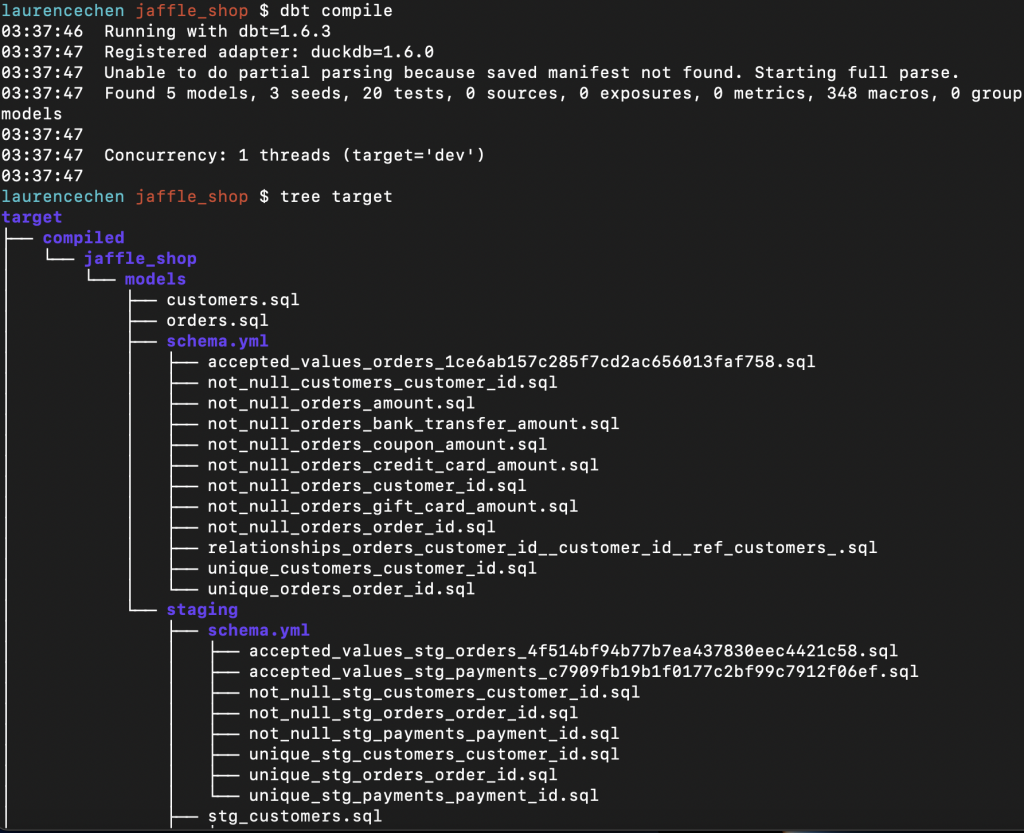
讀者如果跟我一樣喜歡用 terminal 來操作的話,可以考慮下一個 tree 指令,看一下 models 資料夾。
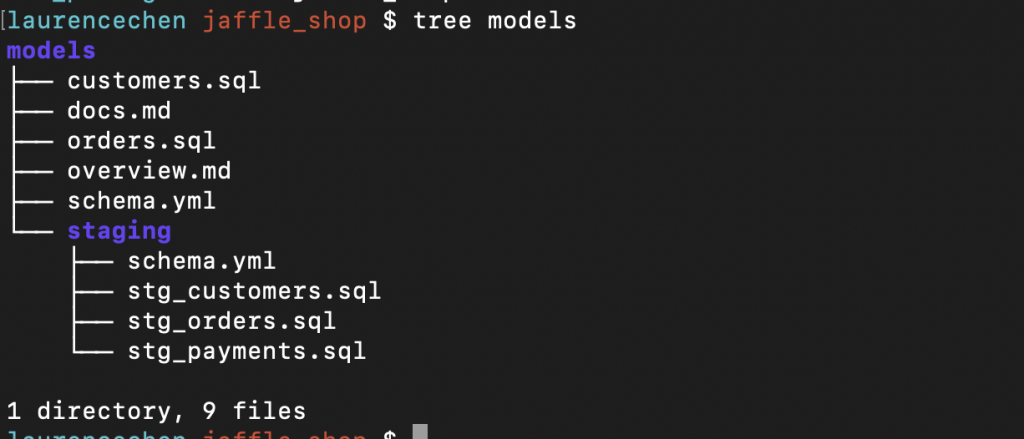
models 資料夾裡,有兩類檔案比較重要:
以 stg_customers.sql 為例子,它的內容是:
with source as (
{#-
Normally we would select from the table here, but we are using seeds to load
our data in this project
#}
select * from {{ ref('raw_customers') }}
),
renamed as (
select
id as customer_id,
first_name,
last_name
from source
)
select * from renamed
讀者可能覺得有點複雜,其實上頭的內容裡,真正有去從資料表讀取資料的一行只有:
select * from {{ ref('raw_customers') }}
其它的行,都只是在改善日後的可維護性而已。
之前我們也有提到過:「一般的 dbt 專案,其實不會常用 dbt seed 指令來匯入大量的資料。」
在實務上,資料倉儲的大部分資料,很可能是分散在不同的命名空間 (schema) 的許多張表 (table) ,而且,這些表是透過所謂的 EL 工具來定期更新的。
若要有效地讀取這些表,必須使用 source 函數,同時,還得去修改 models 資料夾下的 schema.yaml 檔,填入命名空間相關的資訊。
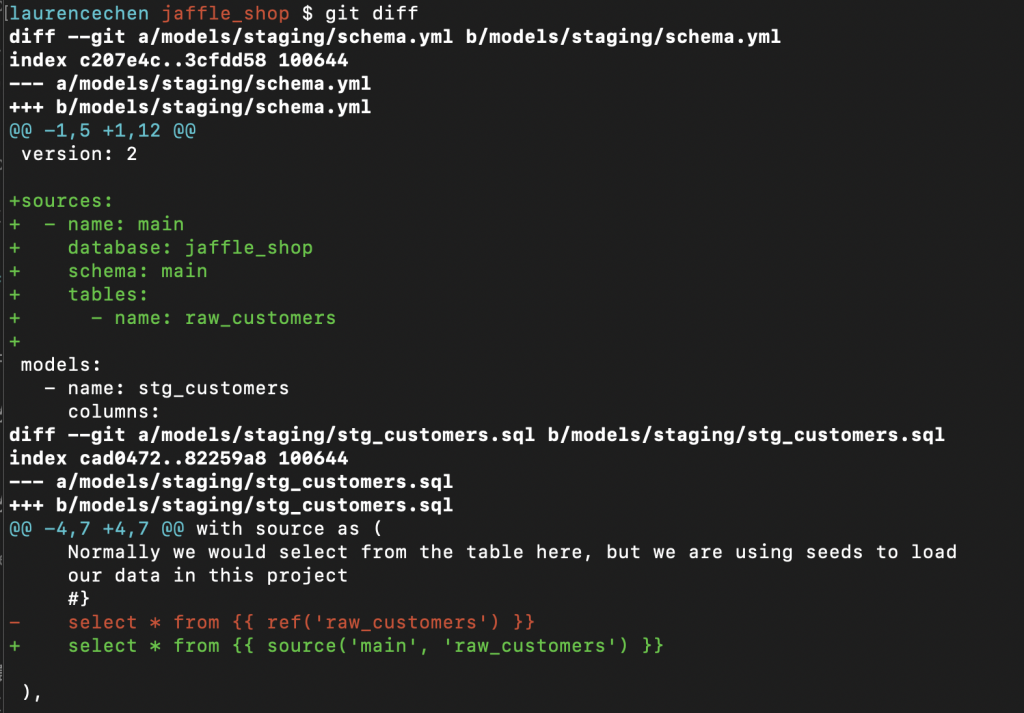
前面的例子裡,{{ ref('raw_customers') }} 是 jinja 語法。在 dbt 支援的 jinja 語法之中,有兩個函數特別重要:
ref 函數 - 如果我們要在一個 .sql 建模裡去讀取「其它視圖」,可以用 ref 函數。source 函數 - 如果我們要在一個 .sql 建模裡去讀取「原始資料表」時,可以用 source 函數。一旦學會了 ref 和 source ,就算是 dbt 入門了,可以開始做一些簡單的專案了。
讀者可能會問,「咦,奇怪,為什麼明明在 SQL 裡,對視圖 (view) 或是對資料表 (table) 下查詢,不是都可以用相同的查詢 (query) 語法嗎?為什麼 dbt 要特別設計兩個不同的函數來區別這兩種使用情境呢?」
這邊最主要的關鍵點在於命名空間 (schema) 與命名的唯一性:
ref 函數只接受單一的引數,即資料建模 (model) 的名稱。source 函數必須接受兩個引數,一個用來連結「命名空間」,另一個則用來連結「原始資料表」。資料轉換層 (transformation layer) 常見的錯誤有三種形式:
要減少這類型的錯誤,有兩件事可以做:
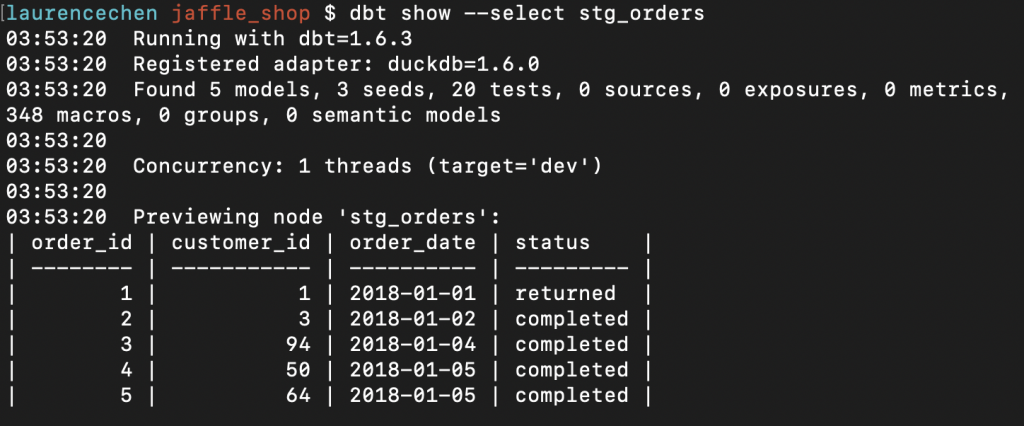
SQL 的語法錯誤,我通常用三種方式來預防與治療。
當手寫的資料建模 (model) 內含 SQL 與 jinja 時,要除錯就有點不那麼直接了。這邊要對 dbt 的運作方式做多一點說明。參考下方的這張圖:
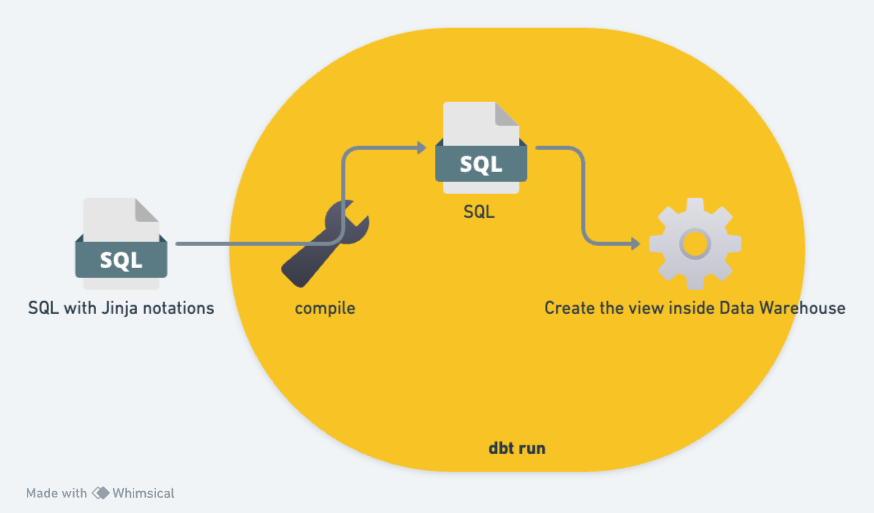
如果我們可以看到在 dbt compile 之後,編譯生成的 pure SQL 檔,距離除錯成功,自然就更近一步。要到哪邊去找呢?
建議可以先下一個 dbt clean 指令,先清除掉所有之前生成的檔案。然後下 dbt compile ,之後就可以在 target 資料夾下找到編譯生成的 pure SQL 檔了。
髒資料算是這三種錯誤裡,最棘手的錯誤。因為很有可能,你在發展資料建模的時候,用的是乾淨的資料,而有一天,突然資料就變髒了。比較可以有效因應髒資料這種錯誤的解決方案,建議使用 dbt test 來設置一些條件,不定時地做自動化檢查。
談「 資料建模」,很自然地就會談到如何處理錯誤,因為我在實務工作之中,總是不停地在除錯。除錯當然也不是這樣子三言兩語可以完全交代清楚的議題。讀者如果對我的除錯方法論有興趣的話,歡迎參考我的書 --- 從錯誤到創新。


 iThome鐵人賽
iThome鐵人賽